
Machine learning, and its yet-to-be-realized more advanced form artificial intelligence (AI), promise to change our world in myriad ways. One example will be disseminating new medical information to physicians.
We’ve all been in waiting rooms while doctors bounce from patient to patient doing their best to help everyone. Once the hands-on patient care is complete, they still need to take notes, do administrative tasks — and they also want to have a life. Oh, and they need to stay current on new treatment methods to have the trust of the Dr. Googles filling their offices.
Until a new procedure or treatment has been around for quite some time, your average doctor isn’t likely to come across it. The information doesn’t transmit quickly, as traditional professional journals are still a primary means of learning. More obscure conditions and treatments get even less coverage and it can be difficult to find information about them in a timely manner.
This is the promise of machine learning in medicine. A computer can tell physicians about new and potentially relevant studies, treatments, procedures, medications, and so on, thus improving patient care. Better informed physicians via faster, more targeted sharing of information without adding more work to already overworked people — it’s a win for doctors and their patients.
There’s just one problem with this — “we” are placing the wrong expectations on machine learning. Machine learning is an algorithm, or formula, that tells the processors what likely matters. The computer then keeps modifying that algorithm to better its results. There is a cognitive disconnect here for most people, myself included, because we are heavily biased to think that machines cannot be wrong.
It seems obvious to most that an incorrect answer in Excel is not an error in the software, but in how a person input the formula. Similarly, if you use Calculator on your iPhone, you never doubt the answer is correct. We don’t back check these things with long division; we have learned over decades that it’s going to be right. We’ve internalized that computers are always right, always accurate.
This isn’t the case for algorithm-based machine learning. We can’t expect the machines will return the correct result every time. Machine learning may lessen the demand for human capital, but we still have to check the work of machines since we are no longer working in black and white answers. Instead, we are working in the nasty reality of interpretation.
As it turns out, humans are quite good at interpreting meaning, so let me ask you a simple question: how would you explain how you know whether or not a tweet is about basketball? How would you explain how you make the determination to a toddler? The question isn’t a yes/no “is this tweet basketball,” the question is asking you to define the parameters you used to determine that a tweet which didn’t include any proper names, or basketball terms, was actually about basketball. We do this in much the same way as a machine learning algorithm - the black box of our brain interprets something as basketball or not by noting patterns, relationships, meanings and the like, but it’s surprisingly difficult to explain exactly how we come to those conclusions. However, we don’t expect this kind of vague behavior from machines. Despite how natural it is in humans, it seems wrong in computers.
At MartianCraft we built a prototype Twitter app to show just this:
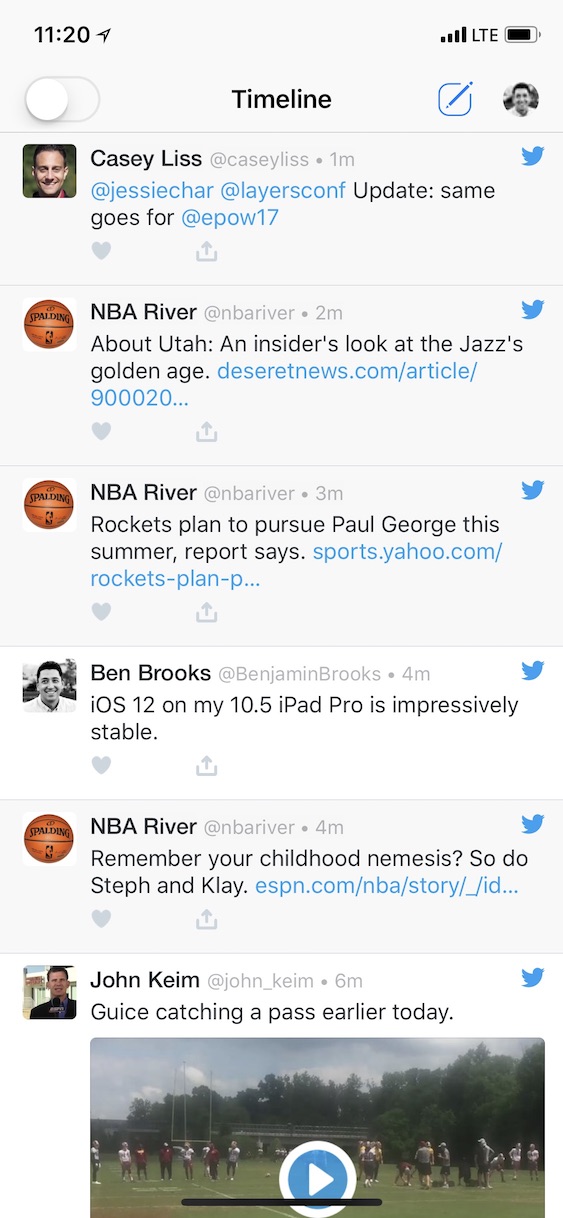
Shown above is our prototype app, with my personal timeline shown. As you can see there are a few obvious basketball tweets in there and some which are not. As a human it’s easy for you to interpret, but what about for a machine? What happens if I switch on that toggle at the top, which will use the trained data set to filter out what our algorithm has taught itself is basketball-related?
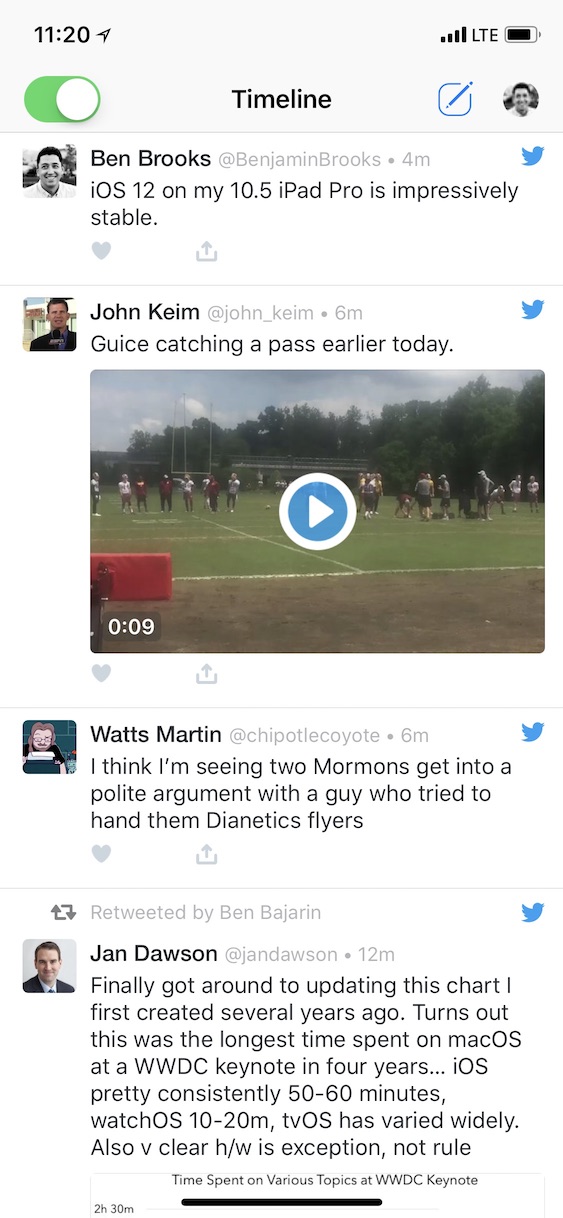
Oops, for some reason — a reason we can’t tease out from the “black box” of our model — the model thought that first tweet was basketball related. Digging into the data we can see what the machine is calculating for itself:
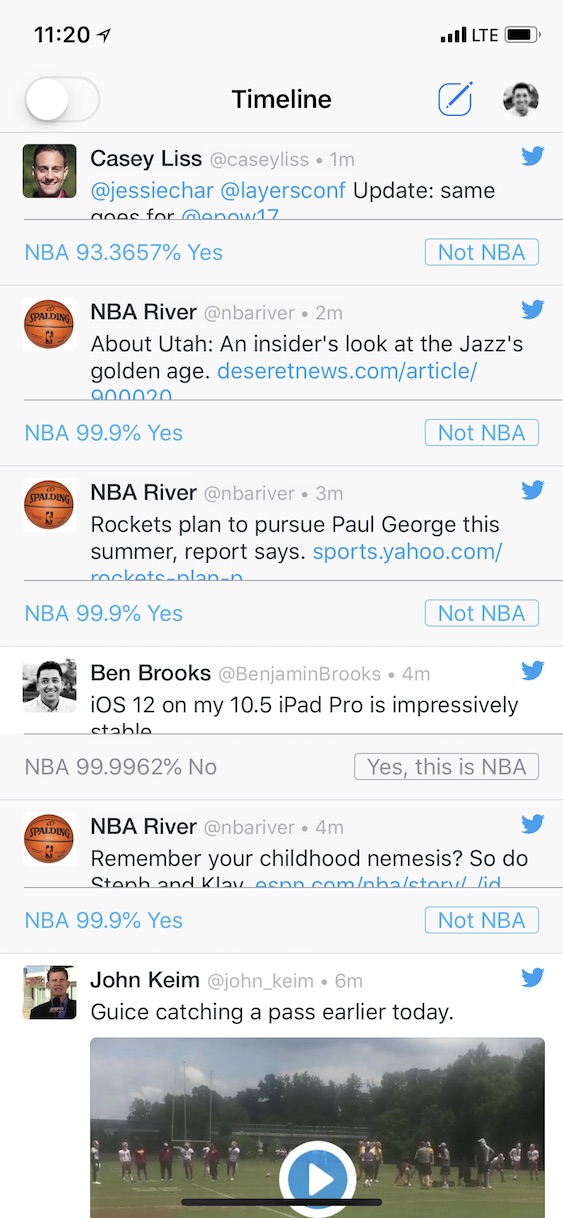
The algorithm is very confident on most of the tweets, but unsure about that first one, showing only 93% confidence that the tweet is NBA-related.
At first blush you would be forgiven for thinking that we had failed to build a machine learning-based client to filter for NBA, but the truth is: we succeeded in meeting perhaps the highest level of accuracy (about 95%) one could hope to attain for such a task on tweets. This is what’s hard to explain about machine learning, because we as humans have learned that machines are nearly infallible. That remains true for many of the common tasks you use a computer for, but not when it comes to machine learning.
At this stage in the development of machine learning, models must be watched, cared for, and corrected constantly to be effective. In the future, they may be more self-sufficient and accuracy may near 100%, but those are not realistic expectations from machine learning right now.
Just because a computer is told to identify and classify “anything basketball on Twitter” doesn’t mean that this machine can explain what classifies something as basketball any better than any of us can explain it to a toddler. A difficult problem for a human remains difficult for a machine, though machines have the benefit of being able to process far more information far more quickly than humans. And that’s where the advantage of machine learning lies. Not yet in the accuracy (though it needs to be mostly accurate) but rather in the speed of processing — which is exactly where computers have always most benefited humans.
This is where we start with machine learning, not by moving mountains to usurp jobs, but by understanding that machine learning is going to require the care of humans for some time to come. It’s not perfect, and we can begin to apply it to simple problems if our expectation is improvement, not perfection.

